一百行代码实现一个简易导表工具
描述
这个是使用python的xlrd库实现的一个简易导lua表格的工具的工具,支持多sheet,相对来说比较简单,原理就是读表拼接字符串,然后生成文件,总代码行数差不多60行,如果不算注释和日志的话应该是只有50行左右。
表格结构
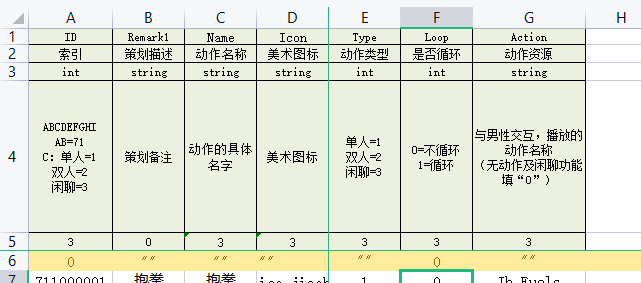
我这边使用的表格结构
- 第一行是字段名称
- 第二次是字段描述
- 第三行是字段类型
- 第四行是字段的可选类型
- 第五行是字段导出筛选(不需要,客户端列,服务器列)
- 第六行是字段的默认值(用来优化LuaTable的方案,使用元表优化法)
核心逻辑
- def format_val :这个函数是格式化数据类型
- def save_to_file :保存字符串到文件
- def parse_excel :导表的核心函数
- def main :主入口,可以从命令行传入参数
1 | import xlrd |
核心导表的结构详细分析
先通过xlrd.open_workbook 打开一个Excel文件
workbook.nsheets读取所有的sheet,遍历sheet导表
fields, describes, field_types, export_filter, 分别读出我们表头定义,这里少了我们的第六行默认数据列,
这个暂时没做,也很简单就10行代码。字段名 描述 对应表格行数 fields 字段合集 1 describes 描述合集 2 field_types 字段类型 3 export_filter 过滤合集 5 这里需要看下我们的表格结构,立马就能明白为什么代码要这样写
```lua
local InteractionTable2 = {
[711000001] = {['ID'] = 711000001, ['Name'] = '抱拳', ['Icon'] = 'ico_jiaohu_dan01', ['Type'] = 1, ['Loop'] = 0, ['Action'] = 'Jh_Fuels',},
return InteractionTable21
2
3
4
5
6
7
8
9
10
6. 看下面的结构你就知道字符串怎么拼接了。
7. ```lua
local sheet名字 = {
[Id] = {
[key1] = val1,
[key2] = val2,
}
}然后遍历我们的sheet的行数 for row in range(sheet.nrows - 6): 注意我们要过滤掉表头
核心逻辑遍历字段 for v in fields.items():
过滤掉不需要的字段 if int(export_filter[v[0]]) != 0:
拼接字符串
拼接描述
返回表格
Git链接
All articles in this blog are licensed under CC BY-NC-SA 4.0 unless stating additionally.
Comment
